Agents und Architekturen
Wie Tools ausgewaehlt werden
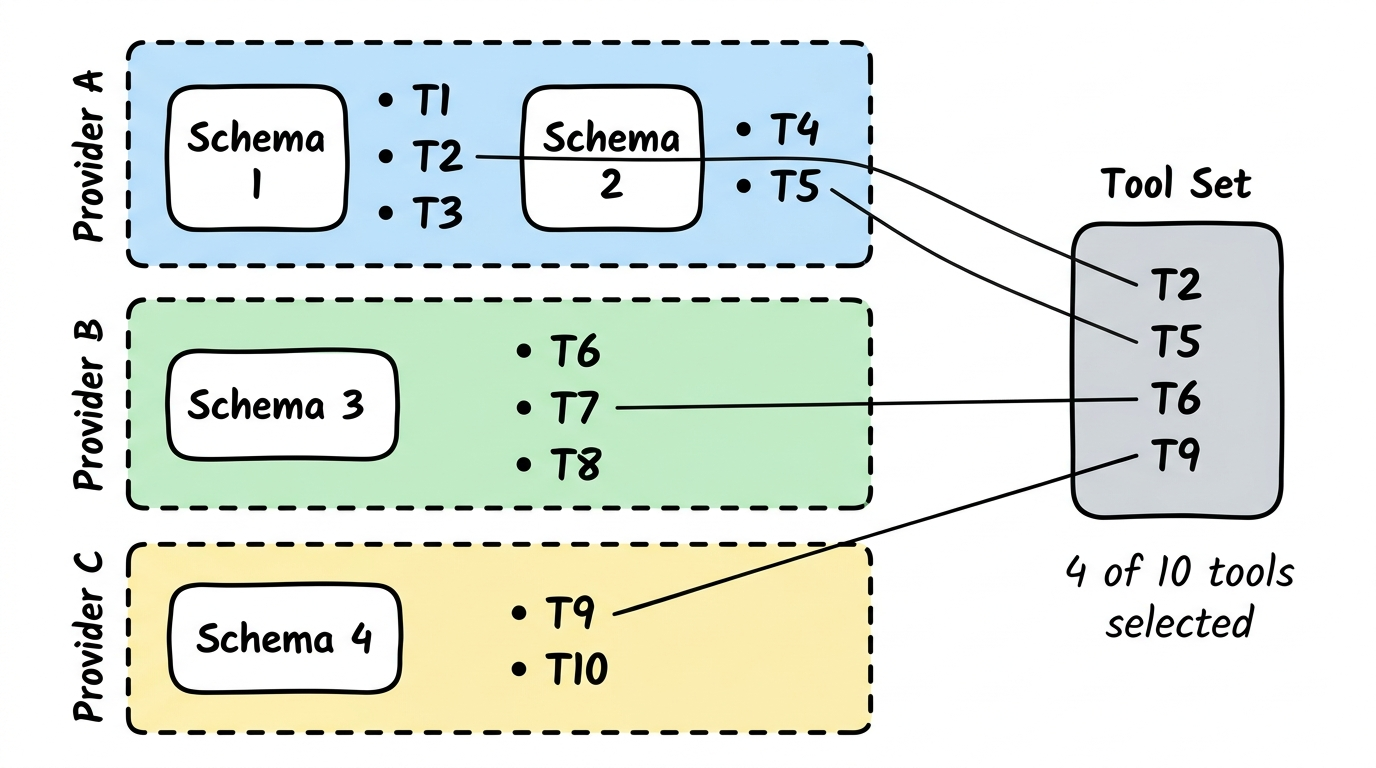
Abschnitt betitelt „Wie Tools ausgewaehlt werden“Aus dem Schema-Katalog werden einzelne Tools ausgewaehlt und zu einem Tool Set zusammengestellt. Nicht alle Tools werden gebraucht — nur die, die fuer den jeweiligen Anwendungsfall relevant sind.
Was ist ein Agent?
Abschnitt betitelt „Was ist ein Agent?“Ein Agent ist mehr als eine einfache Tool-Abfrage. Waehrend ein Tool eine einzelne Frage an eine Datenquelle stellt (“Wie ist das Wetter in Berlin?”), kann ein Agent mehrere Tools kombinieren, nachdenken und selbststaendig entscheiden, welche Informationen er noch braucht.
Das Besondere: Ein Agent hat ein eigenes Sprachmodell (LLM), das fuer ihn denkt. Er ist nicht nur ein Programm das Befehle ausfuehrt, sondern ein Experte der Fragen versteht, Werkzeuge auswaehlt und Antworten formuliert.
Ein Agent besteht aus:
- Einem eigenen LLM — das Sprachmodell, mit dem der Agent denkt und entscheidet
- Einem System-Prompt — definiert das Verhalten: “Du bist ein Mobilitaetsexperte. Beantworte Fragen zu Verbindungen, Wetter und Sharing-Angeboten.”
- Tool-Referenzen — der Agent waehlt sich aus verschiedenen Provider-Schemas die Tools aus, die er braucht. Er nimmt nicht alle, sondern nur die relevanten.
- Tests — pruefen ob die Kombination aus LLM, Prompt und Tools tatsaechlich funktioniert
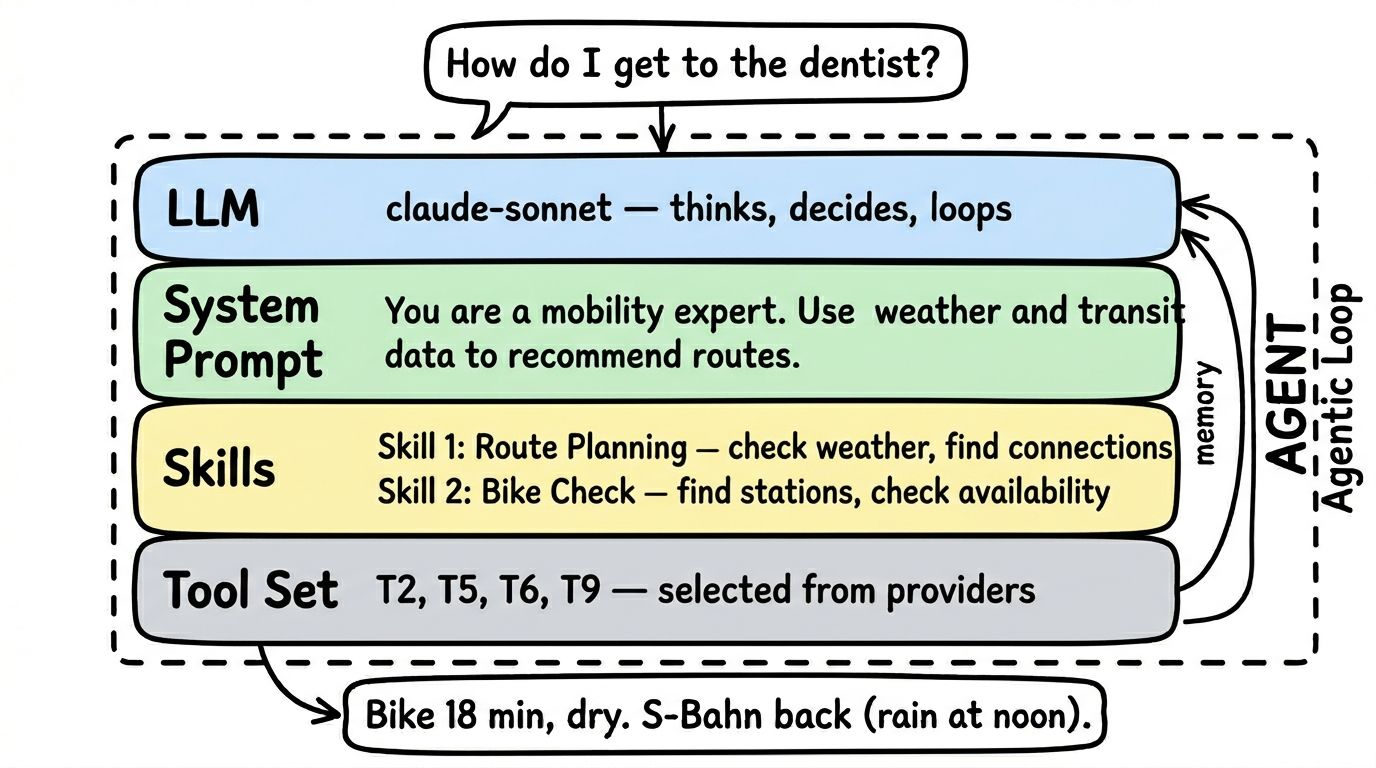
Beispiel: Ein Mobility Agent kombiniert Tools aus dem DB-Fahrplan-Schema (getConnections), dem OpenWeather-Schema (getWeather) und dem nextbike-Schema (findStations). Er hat als LLM Claude Haiku und weiss durch seinen System-Prompt, dass er Mobilitaetsfragen beantworten soll.
Der Agentic Loop
Abschnitt betitelt „Der Agentic Loop“Ein Agent arbeitet nicht linear, sondern in Schleifen. Das ist der zentrale Unterschied zu einer einfachen Tool-Abfrage:
- Frage verstehen — Was will der Nutzer wissen?
- Tool auswaehlen — Welche Daten brauche ich?
- Tool aufrufen — Daten abfragen
- Ergebnis bewerten — Reicht das? Habe ich alles?
- Entscheiden — Fertig → Antwort formulieren. Oder: Noch ein Tool noetig → zurueck zu Schritt 2.
Der Loop laeuft so lange, bis die Antwort vollstaendig ist — oder ein konfiguriertes Maximum an Durchlaeufen erreicht wird.
Warum das wichtig ist: Wenn jemand fragt “Soll ich morgen mit dem Fahrrad oder der S-Bahn fahren?”, muss der Agent:
- Erst das Wetter pruefen (Tool 1)
- Dann die S-Bahn-Verbindungen abfragen (Tool 2)
- Dann pruefen ob es Fahrrad-Stationen in der Naehe gibt (Tool 3)
- Erst dann eine Empfehlung formulieren
Ein einfacher Tool-Call koennte nur einen dieser Schritte machen. Der Agentic Loop macht alle — und denkt dazwischen nach.
Der Preis dafuer: Der Agent braucht sein eigenes LLM. Das kostet Compute. Aber die Antwortqualitaet ist deutlich besser als bei einzelnen Tool-Aufrufen.
Drei Nutzungsarchitekturen
Abschnitt betitelt „Drei Nutzungsarchitekturen“Nicht jede Anfrage braucht einen vollstaendigen Agenten. Es gibt drei Stufen — von einfach bis komplex:
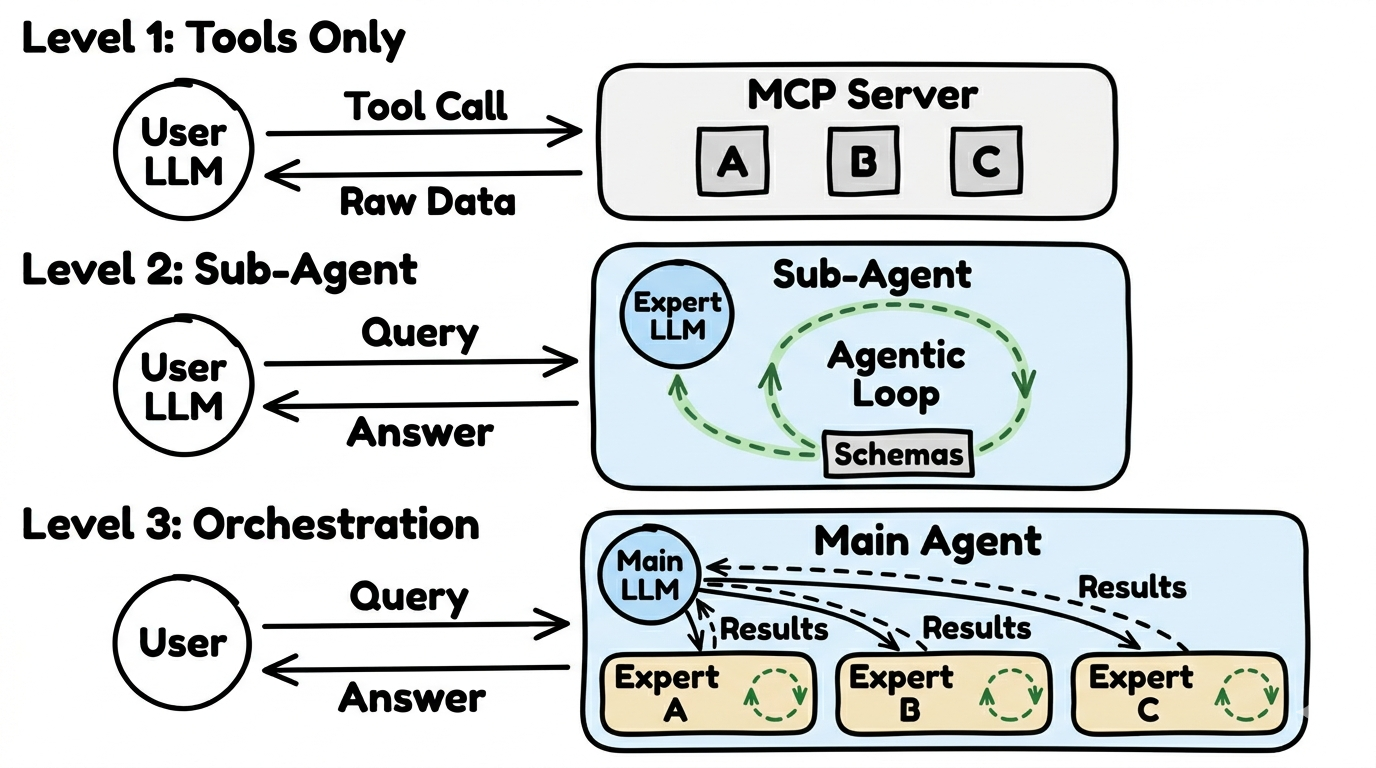
Level 1: Tools Only
Abschnitt betitelt „Level 1: Tools Only“Die einfachste Stufe. Die KI des Nutzers ruft einzelne Tools direkt auf — ohne eigenen Agenten, ohne Schleifen, ohne zusaetzliches LLM.
- Wie es funktioniert: Der Nutzer fragt “Wie ist das Wetter in Berlin?”, die KI erkennt das passende Tool und ruft es auf
- Ergebnis: Rohdaten, die die KI des Nutzers selbst interpretiert
- Vorteil: Schnell, guenstig, funktioniert mit 108+ MCP-Clients
- Nachteil: Keine Kombination mehrerer Datenquellen, keine Schleifen
Level 2: Sub-Agent
Abschnitt betitelt „Level 2: Sub-Agent“Ein spezialisierter Agent mit eigenem LLM. Er hat eigene Tools, eigene Logik und kann den Agentic Loop nutzen.
- Wie es funktioniert: Die Anfrage geht an einen Experten-Agenten, der selbststaendig die richtigen Tools auswaehlt und kombiniert
- Ergebnis: Eine interpretierte, aufbereitete Antwort — nicht nur Rohdaten
- Vorteil: Bessere Antwortqualitaet, Kombination mehrerer Datenquellen
- Nachteil: Braucht ein zusaetzliches LLM, kostet mehr Compute
Level 3: Orchestrierung
Abschnitt betitelt „Level 3: Orchestrierung“Die komplexeste Stufe. Ein Koordinator-Agent verteilt Anfragen an mehrere Sub-Agenten. Jeder Sub-Agent ist Experte fuer sein Thema.
- Wie es funktioniert: Der Koordinator versteht die Frage, entscheidet welche Experten gefragt werden muessen, sammelt deren Antworten und formuliert eine Gesamtantwort
- Ergebnis: Eine kombinierte, optimierte Antwort aus mehreren Fachgebieten
- Vorteil: Komplexe Fragen koennen beantwortet werden, die kein einzelner Agent allein beantworten koennte
- Nachteil: Mehrere LLMs laufen parallel — hoechster Compute-Aufwand
Elicitation: Wenn der Agent Rueckfragen stellt
Abschnitt betitelt „Elicitation: Wenn der Agent Rueckfragen stellt“Nicht jede Frage kann sofort beantwortet werden. “Wie komme ich zum Bahnhof?” — Welcher Bahnhof? Von wo? Zu Fuss oder mit dem Bus?
Elicitation erlaubt dem Agent, strukturierte Rueckfragen zu stellen, bevor er antwortet. Das ist ein Feature des MCP-Protokolls und funktioniert ab Level 2.
Beispiele fuer Rueckfragen:
- “Von welchem Standort moechtest du starten?”
- “Meinst du heute oder morgen?”
- “Soll ich auch Sharing-Angebote beruecksichtigen?”
- “Meinst du Berlin Hauptbahnhof oder Berlin Suedkreuz?”
Warum das so wichtig ist: Ohne Elicitation muss der Agent raten oder mit unvollstaendigen Informationen arbeiten. Mit Elicitation fragt er nach — und die Antwort wird deutlich besser. Der Unterschied ist oft der zwischen einer nuetzlichen und einer nutzlosen Antwort.
Nicht alle Clients unterstuetzen Elicitation. Aktuell sind es 16 MCP-Clients — darunter Claude Desktop, OpenClaw und Codex. Bei Clients ohne Elicitation funktionieren Level 2 und 3 trotzdem — der Agent kann dann nur keine Rueckfragen stellen und arbeitet mit dem, was er hat.
Welche Clients was unterstuetzen: Clients und Kompatibilitaet →
Beispiel: Level 3 in der Praxis
Abschnitt betitelt „Beispiel: Level 3 in der Praxis“Eine typische Level-3-Implementierung nutzt einen Koordinator-Agent, der Anfragen an spezialisierte Sub-Agents weiterleitet. Jeder Sub-Agent hat Zugriff auf bestimmte Schemas und Tools.
Ein Reiseplanungssystem koennte zum Beispiel nutzen:
- Einen Fahrplan-Agent (Zugverbindungen, Flugdaten)
- Einen Wetter-Agent (Vorhersagen, Warnungen)
- Einen Standort-Agent (Geocoding, Points of Interest)
Der Koordinator entscheidet anhand der Nutzerfrage, welche Agents einbezogen werden. Dieses Muster funktioniert in jeder Domaene, in der mehrere Datenquellen kombiniert werden muessen.
Mehr erfahren
Abschnitt betitelt „Mehr erfahren“- Agent-Manifeste und Konfiguration: Agents Uebersicht
- FlowMCP Spezifikation: FlowMCP Spec v3.0.0
- MCP Clients: modelcontextprotocol.io/clients