Warum wir das machen
Vom Webbrowser-Internet zum KI-Internet
Abschnitt betitelt „Vom Webbrowser-Internet zum KI-Internet“Ueber Jahrzehnte war das Browser-Internet dominant — Menschen besuchen Webseiten, klicken Links, fuellen Formulare aus. Daneben gab es das “Hacker-Internet”, in dem technisch versierte Nutzer ueber APIs und Scripts auf Daten zugreifen.
Mit leistungsfaehigen Sprachmodellen entsteht jetzt ein drittes Bild: ein KI-Internet, das im Kern in einem Chat-Interface lebt. Man unterhalt sich mit einer KI — und die KI interagiert im Hintergrund mit Datenquellen und Schnittstellen. Der Nutzer sieht nur das Ergebnis.
Genau hier setzen wir an: Als Bruecke zwischen Menschen und oeffentlichen Datenquellen in diesem neuen KI-Internet. Oeffentlich finanzierte Daten sollen nicht nur von grossen Plattformen genutzt werden, sondern direkt den Menschen zugutekommen, die sie bezahlt haben.
Offene Protokolle statt geschlossener Plattformen
Abschnitt betitelt „Offene Protokolle statt geschlossener Plattformen“Unser Projekt baut auf einem offenen Protokoll auf, nicht auf einer geschlossenen Plattform. Praktisch bedeutet das: Die Schemas, die wir erstellen, sind nicht an einen bestimmten Anbieter gebunden. Andere Projekte oder Behoerden koennen eigene Implementierungen entwickeln und dennoch denselben Schema-Satz verwenden.
Wenn eine Implementierung ausfaellt, kann sie ersetzt werden — ohne Schemas oder Clients zu aendern. Das schafft Unabhaengigkeit und Widerstandsfaehigkeit. Es bedeutet auch: Wir bauen keine proprietaere Plattform, sondern wiederverwendbare Infrastruktur.
Demokratische Teilhabe
Abschnitt betitelt „Demokratische Teilhabe“Wer seine Daten verfuegbar macht, bestimmt mit, auf welcher Grundlage KI-Systeme Empfehlungen geben. Ohne strukturierte Anbindung bleiben oeffentliche Daten bei KI-Entscheidungen aussen vor — und die KI stuetzt sich stattdessen auf Quellen, die der Nutzer nicht kontrolliert.
Wir wollen, dass Buerger:innen ueber eine KI ihrer Wahl Fragen stellen koennen — und die Antworten auf offiziellen Open-Data-Quellen basieren. Zum Beispiel:
- “Wie ist die Feinstaubbelastung in meinem Viertel?” — Die KI ruft echte Messdaten ab und erklaert sie in Alltagssprache
- “Welche kostenlosen Beratungsstellen gibt es in meiner Naehe?” — Die KI listet Stellen mit Kontaktdaten
- “Was hat mein Stadtrat zum Thema Radwege beschlossen?” — Die KI wertet Ratsinformationen aus
Der Nutzer bestimmt, welche Quellen die KI verwendet — nicht die Plattform. Das ist ein fundamentaler Unterschied zu geschlossenen Systemen.
Warum viele Datenquellen?
Abschnitt betitelt „Warum viele Datenquellen?“Eine einzelne Datenquelle beantwortet eine einzelne Frage. Aber echte Fragen im Alltag sind nie einfach.
“Soll ich morgen mit dem Fahrrad zum Zahnarzt fahren?” braucht Wetter, Route, Fahrrad-Verfuegbarkeit und den Kalender. Keine dieser Quellen allein kann die Frage beantworten. Erst die Kombination macht die Antwort nuetzlich.
Ein Datensatz = eine Antwort. Viele Datensaetze = eine nuetzliche Antwort.
Unsere Schemas machen diese Kombination moeglich — ohne dass der Nutzer wissen muss, woher die Daten kommen. Konkrete Beispiele: Use Cases →
Energieeffizienz: Einmal aufbereiten, immer nutzen
Abschnitt betitelt „Energieeffizienz: Einmal aufbereiten, immer nutzen“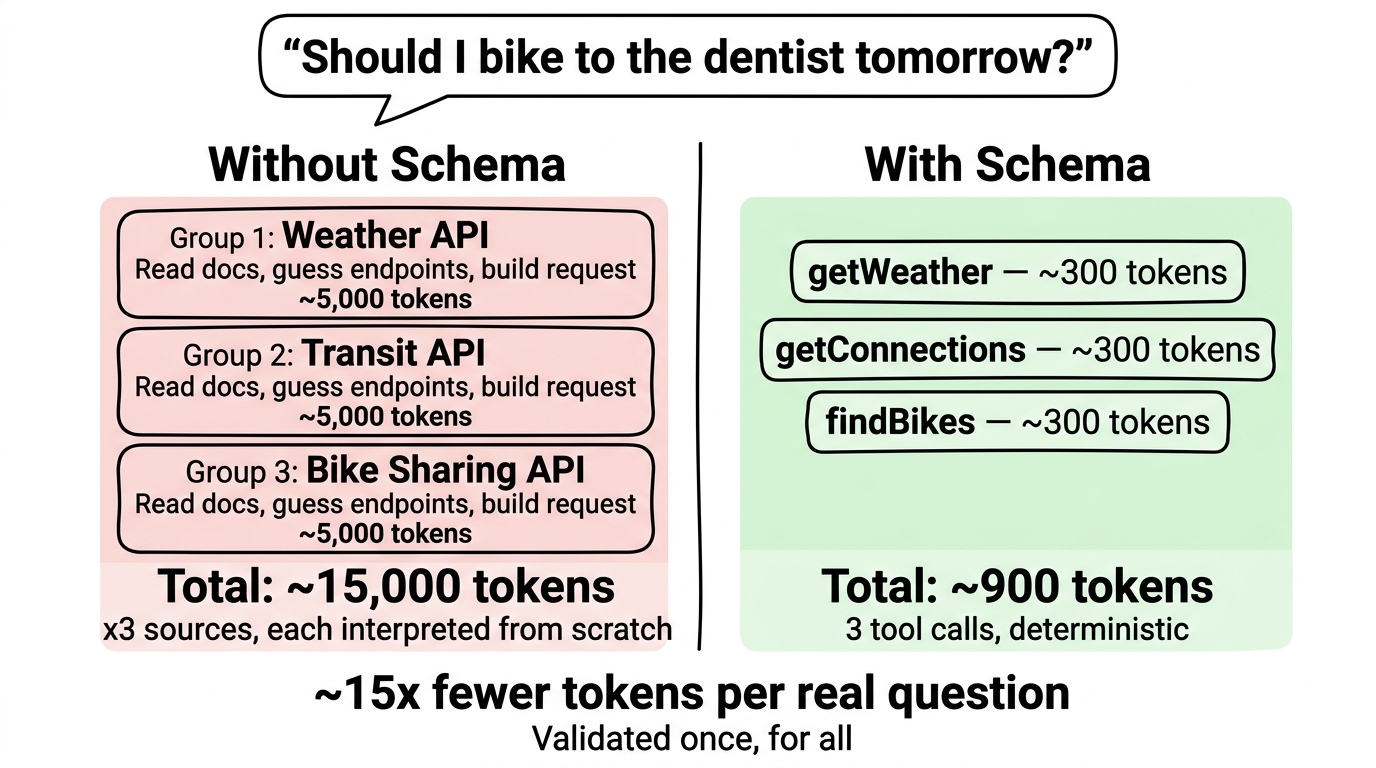
Ohne Schema muesste jede KI bei jeder Anfrage die API-Dokumentation einer Datenquelle von Grund auf lesen und interpretieren. Das kostet bei jeder Anfrage tausende Tokens — und die Ergebnisse sind inkonsistent, weil die KI je nach Zufallsfaktor unterschiedliche Wege waehlt.
Unsere Schema-Aufbereitung ist eine einmalige Investition: Wir analysieren die Datenquelle, beschreiben sie strukturiert, und jede KI kann sie danach effizient nutzen. Eine einzelne Anfrage mit Schema braucht nur einen Bruchteil der Tokens. Ueber hunderte Nutzer und tausende Anfragen summiert sich das zu einer Einsparung um den Faktor 10.
Das liegt an mehreren Effekten: Ohne Schema muss die KI die API-Dokumentation bei jeder neuen Session neu interpretieren. Ueber die Zeit geht das Wissen durch Kompression verloren und muss nachrecherchiert werden. Dazu kommt, dass die KI ohne Schema je nach Zufallsfaktor (Temperature) jeden Tag einen anderen Weg waehlt — mit einem Schema ist der Zugang deterministisch und immer gleich.
Das Prinzip dahinter: “Validated once, for all.” Was einmal sorgfaeltig aufbereitet wurde, steht danach allen zur Verfuegung — konsistent, deterministisch und energieeffizient. Dieses Prinzip wird auch zum Kern unseres Community Hub, in dem die Community selbst Schemas beitragen und validieren kann.
Sicherheit durch Transparenz
Abschnitt betitelt „Sicherheit durch Transparenz“Die Aufbereitung findet oeffentlich statt — als Open Source. Damit ist sie ueberpruefbar und verifizierbar fuer alle. Jeder kann nachvollziehen, wie ein Schema eine Datenquelle anspricht, welche Parameter verwendet werden und was zurueckkommt. Das entspricht modernen Sicherheitsstandards und schafft Vertrauen.
Der Standard-Weg ist so gestaltet, dass er schwer falsch zu benutzen ist — Sicherheit durch Design, nicht durch Dokumentation.
Digitale Souveraenitaet
Abschnitt betitelt „Digitale Souveraenitaet“Nutzer:innen behalten die Kontrolle: Welche Datenquellen aktiv sind, welche Schemas geladen werden. Keine Bindung an eine einzelne Plattform. Das Protokoll ist offen — bei Bedarf koennen alternative Implementierungen eingesetzt werden, ohne Schemas oder Clients zu aendern.
Das gilt auch fuer den Betrieb: Wer moechte, kann unsere Schemas auf einem lokalen Server betreiben — komplett unabhaengig von Cloud-Diensten. Mehr dazu unter Integration.