Community Hub (Coming Soon)
Die Idee
Abschnitt betitelt „Die Idee“Offene Daten sind fuer alle da. Aber die Aufbereitung dieser Daten fuer KI-Systeme ist aufwaendig. Wenn jede KI diese Arbeit selbst macht — die API-Dokumentation lesen, die Endpunkte verstehen, die Parameter erraten — wird enorm viel Compute verschwendet. Und die Ergebnisse sind inkonsistent, weil jede KI einen anderen Weg waehlt.
Unsere Loesung: Ein Schema wird einmal erstellt, einmal validiert und kann danach von jeder KI genutzt werden. Das spart Energie, schafft Konsistenz und macht die Daten zuverlaessig zugaenglich. Wir nennen dieses Prinzip “Validated once, for all”.
Der Community Hub ist der Ort, an dem dieses Prinzip Wirklichkeit wird. Er ist kein zentraler Service und kein eigenes Backend — sondern ein GitHub-Repository, das durch Community-Prozesse wachsen soll.
GitHub als primaere Plattform
Abschnitt betitelt „GitHub als primaere Plattform“Wir setzen bewusst auf GitHub als Plattform fuer den Hub. Die Begruendung:
- Schemas ohne API-Key benoetigen kein Backend. Keine Secrets, keine Server-Sicherheit. Alles kann oeffentlich sein.
- GitHub bietet alles, was wir brauchen: Issues fuer Einreichungen, Pull Requests fuer Reviews, Actions fuer automatische Tests, Discussions fuer Fragen.
- Nachpruefbarkeit: Jede Aenderung ist versioniert und transparent. Wer wann was beigetragen hat, ist fuer immer nachvollziehbar.
- Kein eigenes Backend bedeutet: weniger Wartung, weniger Angriffsfaeche, weniger Kosten.
Was wir dabei offen ansprechen: GitHub ist eine Company, und nicht jeder hat oder will einen Account. Das schraenkt die Teilnahme ein. Langfristig denken wir ueber einen minimalen Vermittlungsdienst nach, der auch Nutzern ohne GitHub-Profil die Teilnahme ermoeglicht. Aber fuer den Start ist GitHub die beste Loesung mit dem geringsten Overhead — und fuer ein Open-Source-Projekt ist ein GitHub-Account zumutbar.
Schemas mit und ohne API-Key
Abschnitt betitelt „Schemas mit und ohne API-Key“| Typ | Im Hub? | Besonderheit |
|---|---|---|
| Ohne API-Key | Ja, vollstaendig | Kann komplett ueber GitHub laufen — kein Backend noetig |
| Mit API-Key | Ja, aber separater Scope | Nutzer muss sich selbst beim Anbieter anmelden. Gekennzeichnet, damit es keine Ueberraschungen gibt |
Zwei Wege, das Projekt zu nutzen
Abschnitt betitelt „Zwei Wege, das Projekt zu nutzen“Nicht jeder muss beitragen. Die meisten Nutzer werden Schemas einfach verwenden — und das ist voellig in Ordnung.
1. Schemas nutzen (Default)
Abschnitt betitelt „1. Schemas nutzen (Default)“Du laedsst validierte Schemas ueber OpenClaw oder die CLI und fragst Daten ab. Kein GitHub-Account noetig, keine Contribution erwartet. Die Schemas sind da, sie funktionieren, du benutzt sie.
2. Schemas beitragen (Opt-in)
Abschnitt betitelt „2. Schemas beitragen (Opt-in)“Du kannst zusaetzlich selbst Schemas erstellen und einreichen. Vielleicht arbeitest du bei einer Organisation, die offene Daten bereitstellt. Vielleicht hast du eine Swagger-Datei und eine KI, die daraus ein Schema machen kann. Der Weg: Deine KI erstellt das Schema nach unserer Spec, du reichst es als Issue ein, die Community prueft es.
Die Besonderheit: Der Compute fuer die Schema-Erstellung kommt vom Nutzer — seine KI macht die Arbeit. Das Spec, also die Regeln wie ein Schema aussehen muss, kommt von FlowMCP. Ohne korrektes Spec wird nichts akzeptiert. Aber wenn es passt, profitiert die gesamte Community davon.
Das ist echtes Crowdsourcing: Nicht nur Feedback geben, sondern produktiv beitragen. Jeder Nutzer mit einer KI ist theoretisch auch ein Entwickler.
Der Kreislauf
Abschnitt betitelt „Der Kreislauf“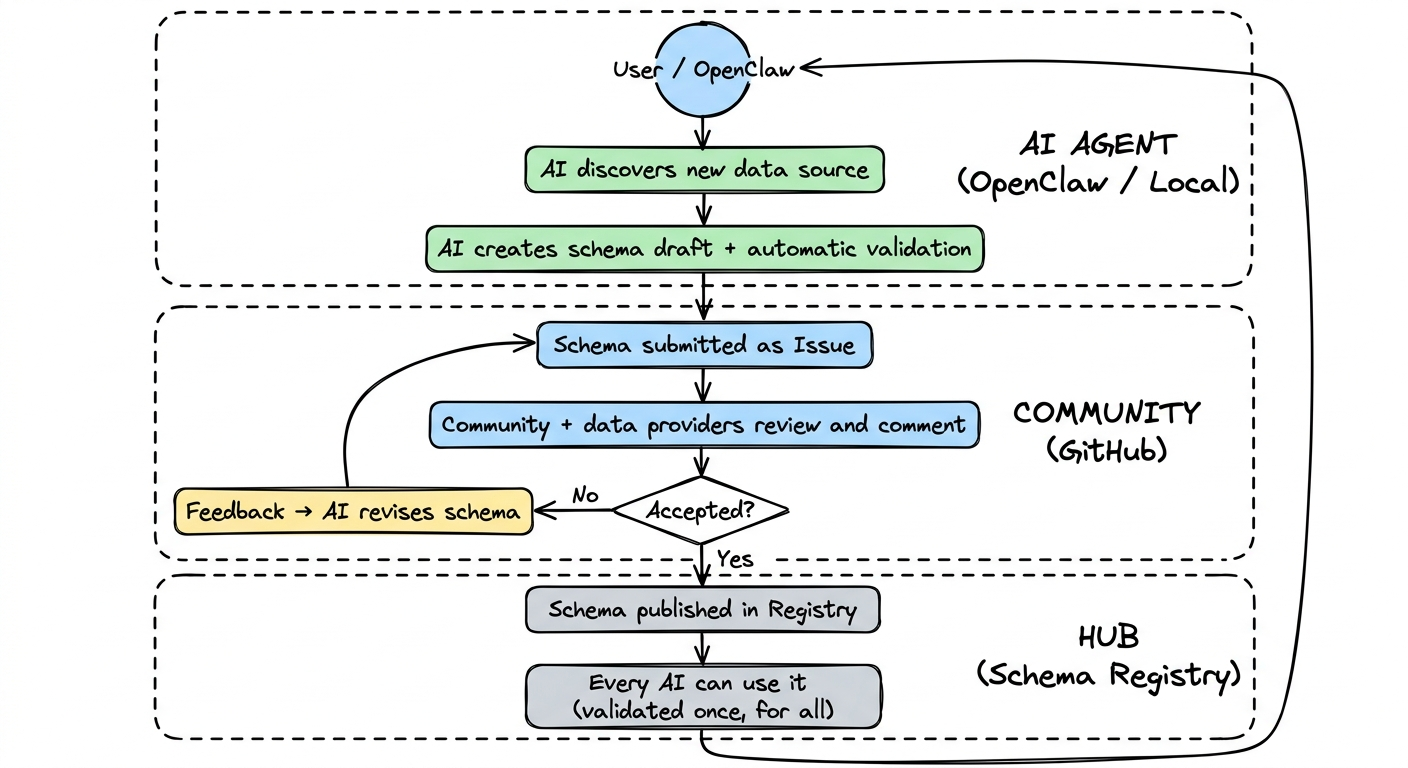
Die Vision dahinter ist ein sich selbst verstaerkender Kreislauf: Eine KI entdeckt eine neue Datenquelle, erstellt einen Schema-Entwurf, reicht ihn als Issue ein, die Community prueft — und bei Akzeptanz steht das Schema allen zur Verfuegung. Durch die Nutzung werden weitere Datenquellen entdeckt, und der Kreislauf beginnt von vorne.
Die Schema-Pipeline: 5 Stufen
Abschnitt betitelt „Die Schema-Pipeline: 5 Stufen“Jedes neue Schema durchlaeuft dieselbe Pipeline. Keine Ausnahmen — auch nicht fuer uns als Projekt-Team. Dieser Prozess stellt sicher, dass nur qualitaetsgepruefte Schemas im Hub landen.
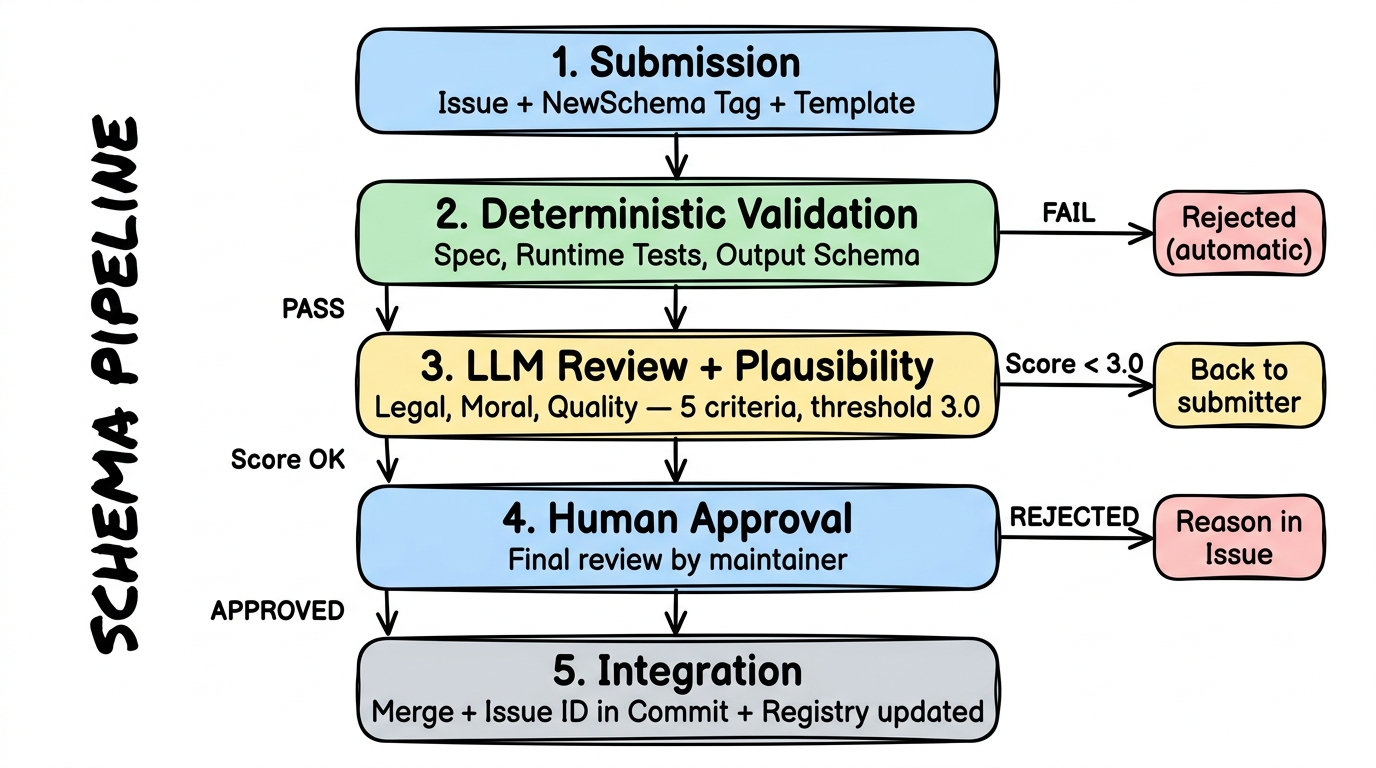
Stufe 1: Einreichung
Abschnitt betitelt „Stufe 1: Einreichung“Ein Nutzer erstellt ein Issue im Schema-Repository mit dem Tag NewSchema. Das Issue folgt einem festen Template — maschinen- und menschenlesbar zugleich:
- Oben: Beschreibung des Providers, verfuegbare Routen, Lizenz-Informationen
- Mitte: Argumente der einreichenden KI — warum dieses Schema, Lizenz-Nachweis, Plausibilitaetseinschaetzung
- Unten: Der eigentliche Schema-Code als Markdown-Codeblock
Der gesamte Prozess ist darauf ausgelegt, dass auch unbekannte KI-Systeme verstaendliche Einreichungen machen koennen.
Stufe 2: Automatische Validierung
Abschnitt betitelt „Stufe 2: Automatische Validierung“Eine GitHub Action wird durch das NewSchema-Tag ausgeloest und prueft deterministisch:
- Ist das Schema parsebar und entspricht der FlowMCP Spec?
- Stimmen die beschriebenen Routen mit dem tatsaechlichen Schema ueberein?
- Bestehen die Runtime-Tests? (echte API-Aufrufe)
- Stimmt der Output mit dem definierten Output-Schema ueberein?
- Hat jede Route mindestens 3 Tests?
Wenn hier etwas fehlschlaegt, wird das Schema sofort abgelehnt — mit automatischem Feedback direkt im Issue. Kein menschlicher Aufwand fuer offensichtlich fehlerhafte Einreichungen.
Stufe 3: KI-Pruefung und Plausibilitaet
Abschnitt betitelt „Stufe 3: KI-Pruefung und Plausibilitaet“Was automatische Tests nicht fangen koennen, prueft eine KI:
- Legale Bedenken: Ist die Lizenz klar und nachpruefbar? Nur weil jemand “MIT-License” schreibt, bedeutet das nicht, dass die Daten tatsaechlich frei verfuegbar sind. Analog zum Kaufrecht: Wenn etwas zu gut klingt, um wahr zu sein, besteht eine Pruefpflicht.
- Moralische Bedenken: Gibt es problematische Inhalte?
- Qualitaet: Sind Beschreibungen sinnvoll? Namenskonventionen eingehalten? Stimmen die zurueckgegebenen Daten mit der Beschreibung ueberein?
Die einreichende KI kann bereits Argumente vorbereitet haben — zum Beispiel: “Die Daten sind amtliche Veroeffentlichungen und damit gemeinfrei. Hier der Link zur Originalquelle.”
Diese Pruefung folgt einem Scoring-System (siehe unten).
Stufe 4: Menschliche Freigabe
Abschnitt betitelt „Stufe 4: Menschliche Freigabe“Ein Maintainer gibt final frei. Der gesamte bisherige Prozess — automatische Tests, KI-Bewertung, Argumente — ist in der Issue-History dokumentiert. Der Mensch prueft, was weder Tests noch KI zuverlaessig beurteilen koennen: Passt dieses Schema zum Projekt? Ist die Datenquelle vertrauenswuerdig?
Der Mensch hat das letzte Wort — immer.
Stufe 5: Integration
Abschnitt betitelt „Stufe 5: Integration“Das Schema wird gemergt. Die Issue-ID wird im Commit referenziert, sodass die Herkunft jedes Schemas rueckverfolgbar ist. Die Registry wird automatisch aktualisiert. Ab diesem Moment kann jeder Nutzer das Schema verwenden.
Qualitaetsstandards und Scoring
Abschnitt betitelt „Qualitaetsstandards und Scoring“
Jedes Schema wird in Stufe 3 nach fuenf Kriterien bewertet, jeweils mit 0 bis 5 Sternen:
| Kriterium | Was wird bewertet |
|---|---|
| Legalitaet | Lizenz klar und plausibel? Datenherkunft nachpruefbar? |
| Qualitaet | Beschreibungen verstaendlich? Namenskonventionen eingehalten? |
| Testabdeckung | Genuegend Tests? Edge Cases beruecksichtigt? |
| Nuetzlichkeit | Relevante Datenquelle? Zuverlaessig? Nachfrage vorhanden? |
| Dokumentation | Issue ausfuehrlich? Argumente nachvollziehbar? Quellen verlinkt? |
Schwellenwerte:
- Der Durchschnitt ueber alle fuenf Kriterien muss mindestens 3.0 Sterne erreichen
- Kein einziges Kriterium darf 0 Sterne haben — wenn ein Bereich komplett durchfaellt, wird das Schema zurueckgewiesen
- Bei Grenzfaellen kann der Einreicher nachbessern
Dieses Scoring-System ist ein erster Entwurf. Die Kriterien und Schwellenwerte werden iterativ verfeinert, sobald echte Einreichungen eingehen. Wichtig ist: Der Prozess ist nachvollziehbar, transparent und in der Issue-History dokumentiert.
Offene Fragen — ehrlich benannt
Abschnitt betitelt „Offene Fragen — ehrlich benannt“Wir wissen, dass dieser Ansatz Herausforderungen mit sich bringt, fuer die es noch keine perfekte Loesung gibt:
- Nicht jeder hat GitHub: Rund 90% der OpenClaw-Nutzer haben heute kein GitHub-Profil. Langfristig planen wir einen minimalen Vermittlungsdienst, damit auch Nutzer ohne GitHub beitragen koennen. Fuer den Start setzen wir auf GitHub Issue Templates als niedrigste Huerde.
- Fraud und Qualitaet: Wenn jede KI Schemas einreichen kann, kommen auch fehlerhafte oder boesartige Einreichungen. Deshalb die 5-Stufen-Pipeline: Automatische Tests fangen das Offensichtliche, KI-Pruefung deckt Subtileres auf, und am Ende entscheidet ein Mensch.
- Skalierung: Wie viele Einreichungen kann ein kleines Team pruefen? Das haengt davon ab, wie gut die automatischen Stufen 2 und 3 funktionieren. Je besser die Automatisierung, desto mehr kann die Community wachsen.
Wir kommunizieren diese offenen Punkte bewusst transparent. Ein Projekt, das vorgibt, alle Antworten zu haben, ist nicht glaubwuerdig. Eines, das die richtigen Fragen stellt und an Loesungen arbeitet, schon.
Mitmachen
Abschnitt betitelt „Mitmachen“Es gibt verschiedene Wege, zum Projekt beizutragen:
- Datenpartner werden: Du hast Zugang zu oeffentlichen Daten und moechtest sie fuer KI-Systeme zugaenglich machen? Team kennenlernen →
- Schemas beitragen: Du hast eine KI und eine Datenquelle? Erstelle ein Schema nach der FlowMCP Spec und reiche es als Issue ein.
- Feedback geben: Etwas funktioniert nicht? Eine Datenquelle fehlt? Issues auf GitHub sind der richtige Ort.
Das Schema-Repository: github.com/flowmcp/flowmcp-schemas-public