Why We Do This
From the Web Browser Internet to the AI Internet
Section titled “From the Web Browser Internet to the AI Internet”For decades, the browser internet was dominant — people visit websites, click links, fill out forms. Alongside it existed the “hacker internet,” where technically skilled users access data through APIs and scripts.
With powerful language models, a third picture is now emerging: an AI internet that lives at its core in a chat interface. You talk to an AI — and the AI interacts with data sources and interfaces in the background. The user sees only the result.
This is exactly where we come in: as a bridge between people and public data sources in this new AI internet. Publicly funded data should not only be used by large platforms, but directly benefit the people who paid for it.
Open Protocols Instead of Closed Platforms
Section titled “Open Protocols Instead of Closed Platforms”Our project builds on an open protocol, not a closed platform. In practice, this means: the schemas we create are not tied to any specific provider. Other projects or government agencies can develop their own implementations and still use the same schema set.
If an implementation fails, it can be replaced — without changing schemas or clients. This creates independence and resilience. It also means: we are not building a proprietary platform, but reusable infrastructure.
Democratic Participation
Section titled “Democratic Participation”Those who make their data available help shape the basis on which AI systems make recommendations. Without structured connections, public data is left out of AI decisions — and the AI relies instead on sources the user does not control.
We want citizens to be able to ask questions through an AI of their choice — with answers based on official open data sources. For example:
- “What is the air quality in my neighborhood?” — The AI retrieves real measurement data and explains it in everyday language
- “Which free counseling centers are near me?” — The AI lists centers with contact information
- “What did my city council decide about bike lanes?” — The AI evaluates council information
The user decides which sources the AI uses — not the platform. This is a fundamental difference from closed systems.
Why Many Data Sources?
Section titled “Why Many Data Sources?”A single data source answers a single question. But real questions in everyday life are never simple.
“Should I bike to the dentist tomorrow?” needs weather, route, bike availability, and the calendar. None of these sources alone can answer the question. Only the combination makes the answer useful.
One data source = one answer. Many data sources = a useful answer.
Our schemas make this combination possible — without the user needing to know where the data comes from. Concrete examples: Use Cases →
Energy Efficiency: Prepare Once, Use Forever
Section titled “Energy Efficiency: Prepare Once, Use Forever”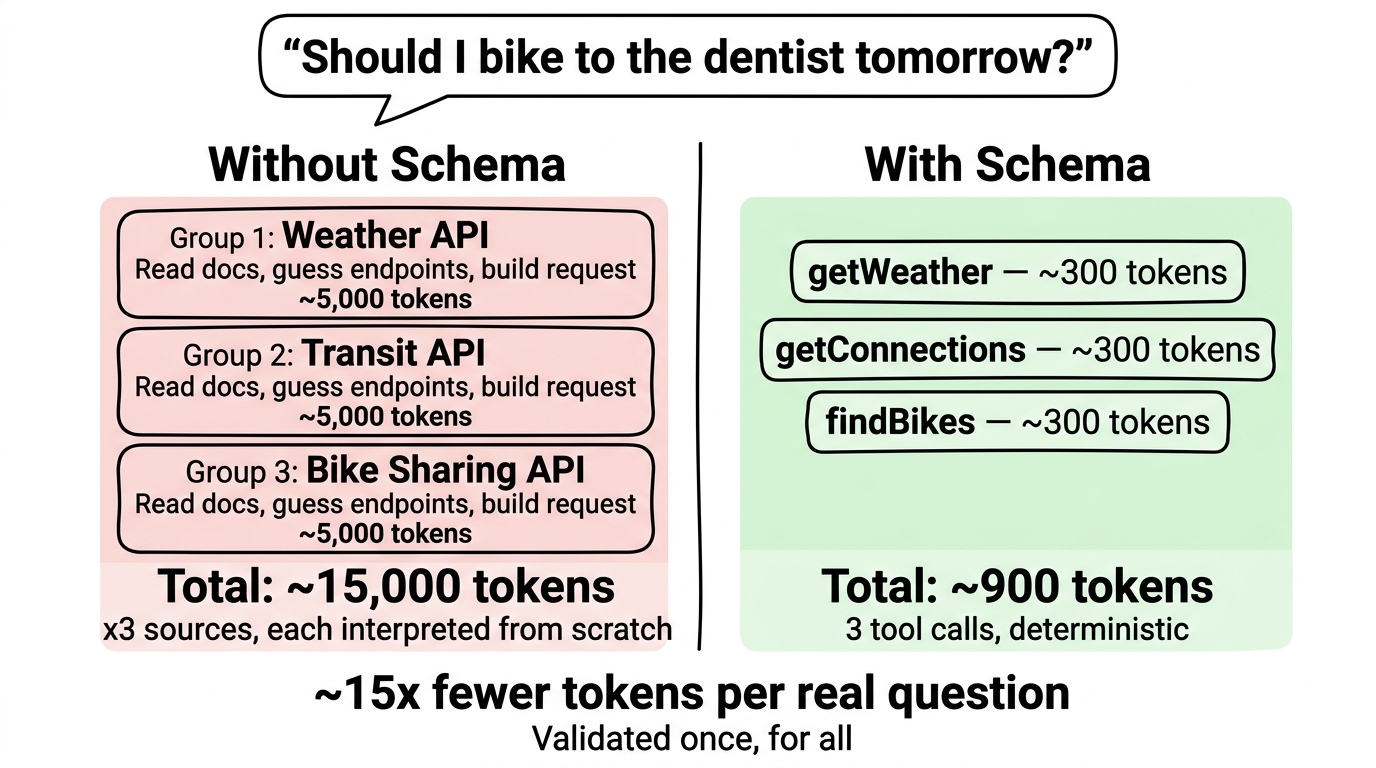
Without a schema, every AI would have to read and interpret the API documentation of a data source from scratch with every request. This costs thousands of tokens per request — and results are inconsistent because the AI takes different approaches depending on randomness factors.
Our schema preparation is a one-time investment: we analyze the data source, describe it in a structured way, and every AI can then use it efficiently. A single request with a schema requires only a fraction of the tokens. Across hundreds of users and thousands of requests, this adds up to savings by a factor of 10.
This is due to several effects: without a schema, the AI must reinterpret the API documentation with every new session. Over time, knowledge is lost through compression and must be re-researched. Additionally, without a schema, the AI takes different paths each day depending on randomness (temperature) — with a schema, access is deterministic and always the same.
The principle behind it: “Validated once, for all.” What has been carefully prepared once is available to everyone afterward — consistent, deterministic, and energy-efficient. This principle also becomes the core of our Community Hub, where the community itself can contribute and validate schemas.
Security Through Transparency
Section titled “Security Through Transparency”Preparation happens publicly — as open source. This makes it auditable and verifiable for everyone. Anyone can see how a schema accesses a data source, which parameters are used, and what comes back. This meets modern security standards and builds trust.
The default path is designed to be hard to use wrong — security by design, not by documentation.
Digital Sovereignty
Section titled “Digital Sovereignty”Users retain control: which data sources are active, which schemas are loaded. No lock-in to any single platform. The protocol is open — alternative implementations can be used if needed, without changing schemas or clients.
This also applies to operations: those who want to can run our schemas on a local server — completely independent from cloud services. More at Integration.