About
FlowMCP is a schema format for standardising data-source access — write the connection to an API once, and every AI agent reuses it through one uniform interface.
FlowMCP started as a way to attach multiple data sources to a single MCP server. Today it is a format: a way to describe, normalise, and unify the tools an AI agent uses to reach a data source. A schema is written once and reused everywhere, so the model never has to re-figure-out how an API connects. The request can be reshaped before and after the call, so tools from very different sources end up looking alike to the model — and the schema is kept separate from its grading and its security test, so you can load a schema and run the security check on its own. AI agents call FlowMCP, never the underlying APIs directly, and your API keys stay in your control.
What FlowMCP is — and isn’t
Section titled “What FlowMCP is — and isn’t”What it is
Section titled “What it is”| Aspect | Description |
|---|---|
| Primitive idea | A flow of data — from heterogeneous sources, through normalised schemas, into AI pipelines |
| Schema format | One declaration shape for any data source; the same format drives the CLI, MCP server mode, and the add-on toolkits |
| Primary use | CLI tool — no MCP client holds 1608 tools in context, the CLI loads them dynamically |
| Secondary use | MCP server mode still supported, but not the default |
| Key isolation | Keys live in FlowMCP, never in the AI context — the AI sees calls and answers, never credentials |
| Reverse search | Schemas register themselves in Shared Lists like “Ethereum Mainnet” or “Berlin”, so an AI can ask which schemas cover a given topic |
| v4 | Skills, Prefill, Selections, Output-Schema, Pipes |
| v4.1+ Add-ons | Four external toolkit add-ons extend FlowMCP — geo-gtfs-toolkit (transit/GTFS), geo-geojson-toolkit and geo-csv-tsv-toolkit (URL → in-memory geodata), and geo-overpass-toolkit (live OpenStreetMap queries) |
| Data classes | Crypto (EVM, Solana, DeFi, Identity, NFT), Open Data (DE/EU), Weather/Geo, Web3 Social, News, Dev-Tools |
What it isn’t (anymore)
Section titled “What it isn’t (anymore)”| Misconception | Reality |
|---|---|
| ”An MCP server” | No — a format. MCP server mode is one optional consumer of it; the CLI is the default. |
| ”A Swagger / OpenAPI spec” | More than that. Swagger describes a single API; FlowMCP unifies access across sources — reshaping the request before and after the call, and keeping schema, grading, and security separate. |
| ”A crypto library” | Started there, broadened with open data since October 2025. |
| ”An API wrapper collection” | No — the engine is central, schemas are thin declarations. One engine audit covers thousands of endpoints. |
| ”An API key manager” | Not primary. Key management is a side effect of separating AI from key. |
Why we built it
Section titled “Why we built it”The problem
Section titled “The problem”Open data exists in vast quantity — transit schedules, weather, government records, geodata, environment data. It is also scattered across hundreds of portals, in different formats, behind different access methods. For humans, finding the right data is tedious. For AI agents, it is nearly impossible — without prior preparation.
What FlowMCP does
Section titled “What FlowMCP does”FlowMCP makes this preparation once, for all:
- Open protocols instead of closed platforms. A failed implementation can be replaced without changing schemas or clients.
- One source = one answer. Many sources = a useful answer. Real questions need combinations.
- Energy efficiency. Without a schema, every AI re-reads API documentation per request — thousands of tokens, inconsistent results. A schema is a one-time investment: every AI then uses it efficiently. Across thousands of requests, ~10x energy savings.
- Security through transparency. Schemas are open source, auditable, verifiable.
How it looks
Section titled “How it looks”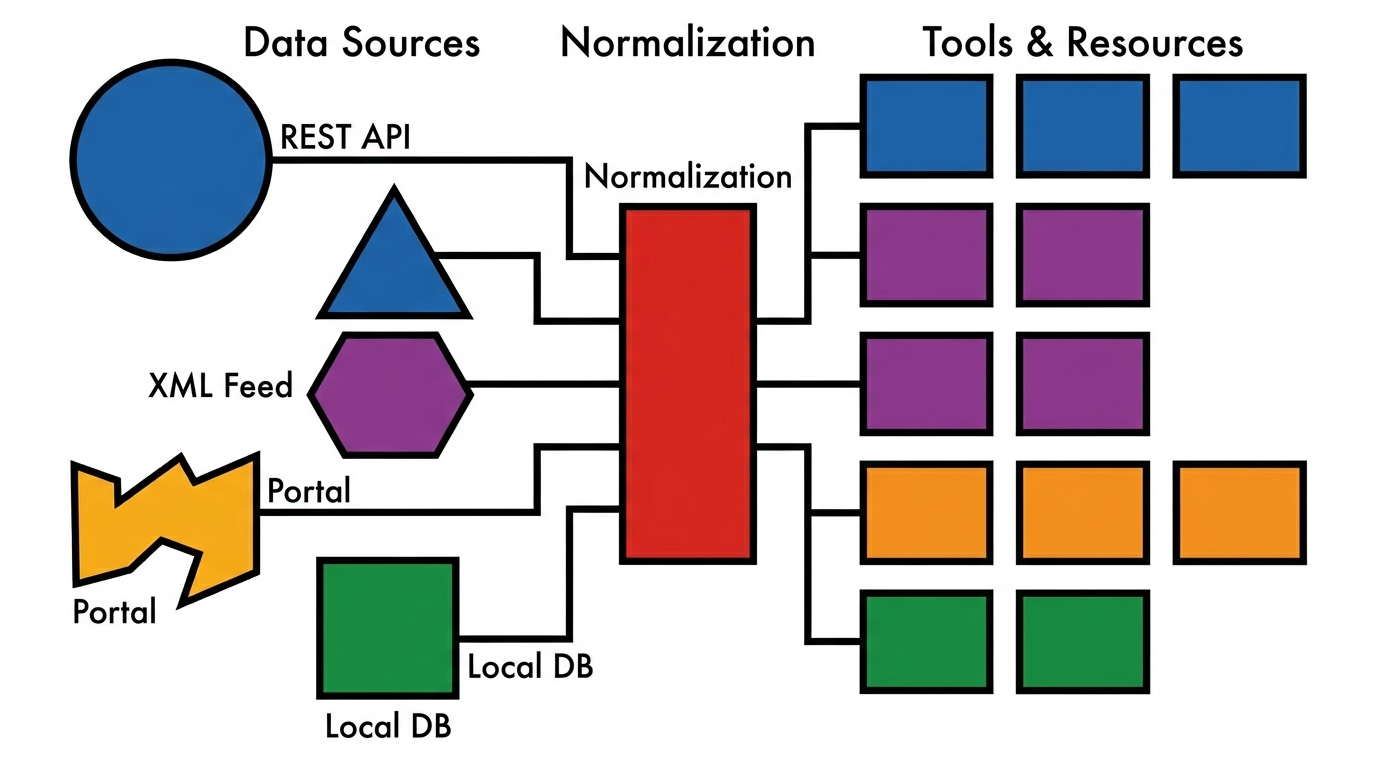
Use cases
Section titled “Use cases”Two scenarios that show FlowMCP + AI in action — not how to build an agent, but how FlowMCP turns scattered data into one answer.
- Deep Research — A research tool or planning software connects an agent. The agent queries FlowMCP for relevant data sources across open data portals, government APIs, and crypto catalogs in seconds.
- Mobility — Catching the Connection — A live trip planner combines static GTFS (via the
geo-gtfs-toolkitv4.1 add-on) with real-time delay data. One CLI call, one answer.
Production posture
Section titled “Production posture”| Signal | Status |
|---|---|
| License | MIT — use, fork, distribute |
| Source | github.com/FlowMCP — active repositories |
| Test coverage | Per repo, published via Codecov |
| Spec version | v4 active, v4.1 add-on layer, v3 in archive |
| Schema lifecycle | Defined per provider (Lifecycle docs in spec) |
| Maintainer status | Visible — see Team for contact |
Trust signals
Section titled “Trust signals”- Open source from day one. Schemas, core, CLI — all MIT, all on GitHub.
- Audit one engine, cover thousands of endpoints. The engine is central; schemas are thin declarations.
- API keys stay with you. FlowMCP holds keys at runtime — the AI sees calls and answers, never credentials.
- Spec evolution is documented. v3 → v4 → v4.1 changes live in the CHANGELOG.
Community
Section titled “Community”FlowMCP is open from day one — every schema, every CLI feature, every spec rule lives on GitHub. The schema library grows through contributions.
- Contribute a schema — Open a PR in FlowMCP/flowmcp-schemas-public following the v4 spec. The CLI validates locally before submission.
- Report an issue or request a schema — github.com/FlowMCP — file in the repo that matches the area (core, CLI, schemas, docs).
- Roadmap — Now / Next / Later. Shows what is shipping now, what is queued, and what we have deliberately chosen not to build. The Roadmap is the contract — anything on it is committed, anything not on it is not silently in progress.